Create Your Own Neural Network From The Scratch (A.I - 101)
Our Community
Regional Communities
Navigation
Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.
Note: This feature may not be available in some browsers.
More options
Style variation
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Create Your Own Neural Network From The Scratch (A.I - 101)
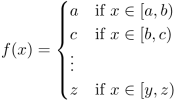
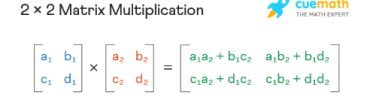
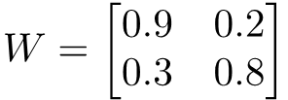
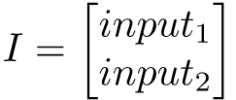
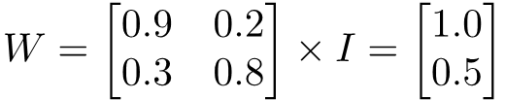
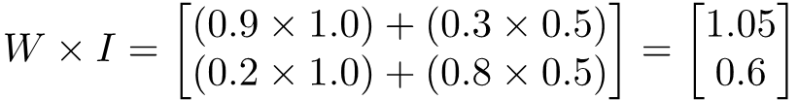
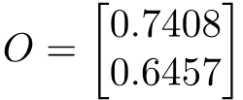
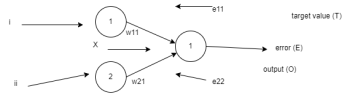
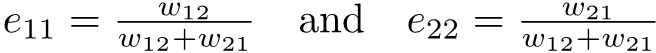
Kuchwizzy
JF-Expert Member
- Oct 1, 2019
- 1,193
- 2,599
- Thread starter
- #39
<div class="bbWrapper"></div>
Attachments
-
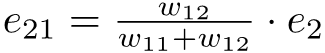 equation (31).png2.7 KB · Views: 0
equation (31).png2.7 KB · Views: 0 -
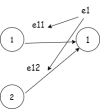 NN-diagram-3.drawio.png16.3 KB · Views: 0
NN-diagram-3.drawio.png16.3 KB · Views: 0 -
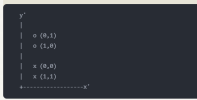
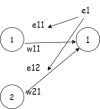 NN-diagram-3.drawio (1).png18.5 KB · Views: 1
NN-diagram-3.drawio (1).png18.5 KB · Views: 1 -
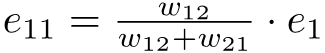 equation (27).png2.6 KB · Views: 2
equation (27).png2.6 KB · Views: 2 -
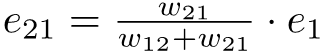 equation (28).png2.7 KB · Views: 0
equation (28).png2.7 KB · Views: 0 -
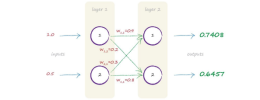
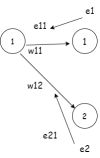 NN-diagram-3.drawio (2).png19.5 KB · Views: 0
NN-diagram-3.drawio (2).png19.5 KB · Views: 0 -
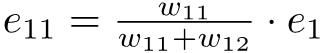 equation (29).png2.4 KB · Views: 0
equation (29).png2.4 KB · Views: 0 -
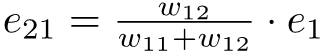 equation (30).png2.6 KB · Views: 0
equation (30).png2.6 KB · Views: 0